Purpose
Return value
Syntax
=MODE.SNGL(number1,[number2],...)
- number1 - A number or cell reference that refers to numeric values.
- number2 - [optional] A number or cell reference that refers to numeric values.
Using the MODE.SNGL function
The MODE.SNGL function returns the most frequently occurring number in a set of numeric data. If supplied data does not contain any duplicate numbers, the MODE.SNGL function returns a #N/A error.
The MODE.SNGL function takes multiple arguments in the form number1 , number2 , number3 , etc. Arguments can be a hardcoded constant, a cell reference, or a range, in any combination. MODE.SNGL ignores empty cells, text values, and the logical values TRUE and FALSE. The MODE function will accept up to 254 separate arguments.
Examples
In the example shown, the formula in D5 is:
=MODE.SNGL(B5:B14) // returns 95
MODE.SNGL returns the most frequently occurring number in supplied data. For example,
=MODE.SNGL(1,2,4,4,5,5,5,6) // returns 5
=MODE.SNGL(7,8,9,7,9) // returns 7
If there are no duplicate numbers, the MODE function returns the #N/A error:
=MODE.SNGL(7,9,6,5,3,1,0) // returns #N/A
Note: MODE will return a single value even when there are multiple modes, to return a list of all modes, see the MODE.MULT function
Notes
- If supplied data does not contain duplicate numbers, MODE.SNGL returns #N/A
- MODE.SNGL ignores empty cells, the logical values TRUE and FALSE, and text .
- Arguments can be numbers, names, arrays , or references.
Purpose
Return value
Syntax
=NORM.DIST(x,mean,standard_dev,cumulative)
- x - The input value x.
- mean - The center of the distribution.
- standard_dev - The standard deviation of the distribution.
- cumulative - A boolean value that determines whether the probability density function or the cumulative distribution function is used.
Using the NORM.DIST function
The NORM.DIST function returns values for the normal probability density function (PDF) and the normal cumulative distribution function (CDF). For example, NORM.DIST(5,3,2,TRUE) returns the output 0.841 which corresponds to the area to the left of 5 under the bell-shaped curve described by a mean of 3 and a standard deviation of 2. If the cumulative flag is set to FALSE, as in NORM.DIST(5,3,2,FALSE), the output is 0.121 which corresponds to the point on the curve at 5.
=NORM.DIST(5,3,2,TRUE)=0.841
=NORM.DIST(5,3,2,FALSE)=0.121
The output of the function is visualized by drawing the bell-shaped curve defined by the input to the function. If the cumulative flag is set to TRUE, the return value is equal to the area to the left of the input. If the cumulative flag is set to FALSE, the return value is equal to the value on the curve.
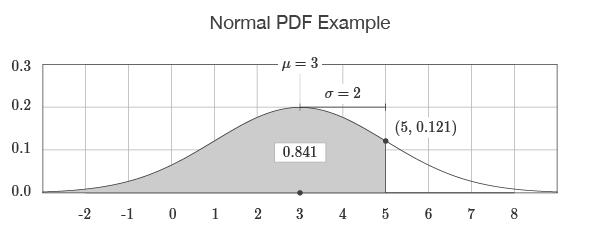
Explanation
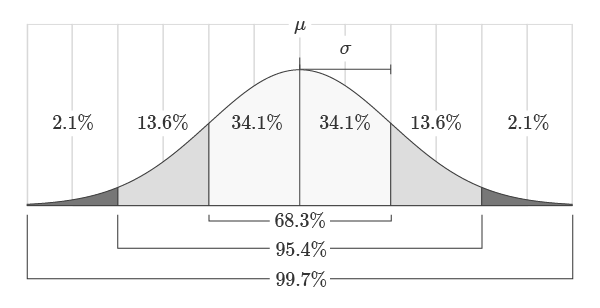
The normal PDF is a bell-shaped probability density function described by two values: the mean and standard deviation. The mean represents the center or “balancing point” of the distribution. The standard deviation represents how spread out the distribution is around the mean. The area under the normal distribution is always equal to 1 and is proportional to the standard deviation as shown in the figure below. For example, 68.3% of the area will always lie within one standard deviation of the mean.
Probability density functions model problems over continuous ranges. The area under the function represents the probability of an event occurring in that range. For example, the probability of a student scoring exactly 93.41% on a test is very unlikely. Instead, it is reasonable to compute the probability of the student scoring between 90% and 95% on the test. Assuming that the test scores are normally distributed, the probability can be calculated using the output of the cumulative distribution function as shown in the formula below.
=NORM.DIST(95,μ,σ,TRUE)-NORM.DIST(90,μ,σ,TRUE)
In this example, if we substitute a mean of 80 in for μ and a standard deviation of 10 in for σ , then the probability of the student scoring between 90 and 95 out of 100 is 9.18%.
=NORM.DIST(95,80,10,TRUE)-NORM.DIST(90,80,10,TRUE)=0.0918
Images courtesy of wumbo.net .
