Purpose
Return value
Syntax
=TAKE(array,[rows],[col])
- array - The source array or range.
- rows - [optional] Number of rows to return as an integer.
- col - [optional] Number of columns to return as an integer.
Using the TAKE function
The TAKE function returns a subset of a given array. The size of the array returned is determined by separate rows and columns arguments. When positive numbers are provided for rows or columns, TAKE will retrieve values from the start or top of the array. Negative numbers take values from the end or bottom of the array.
The TAKE function takes three arguments: array , rows , and columns . Array is required, along with at least one value for rows or columns . Array can be a range or an array from another formula. Rows and columns can be negative or positive integers. Positive numbers take values from the start of the array; negative numbers take values from the end of the array. Both rows and columns default to total rows and columns. If no value is supplied, TAKE will return all rows/columns in the result.
Basic usage
To use TAKE, provide an array or range , and a value for rows and/or columns:
=TAKE(array,3) // get first 3 rows
=TAKE(array,,3) // get first 3 columns
=TAKE(array,3,2) // get first 3 rows and 2 columns
Notice in the second example above, no value is provided for rows .
Take from start
To get rows or columns from the start of a range or array, provide positive numbers for rows and columns. In the worksheet below, the formula in F3 is:
=TAKE(B3:D11,3)
The TAKE function returns the first 3 rows from B3:D11. The formula in F8 is:
=TAKE(B3:D11,4,2)
The TAKE function returns the first 2 columns of the first 4 rows.
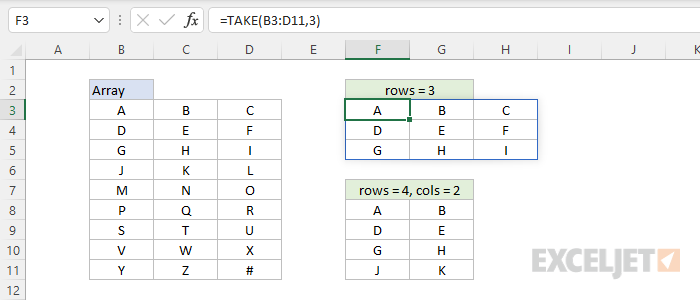
Notice that if a number for rows or columns is not provided, TAKE returns all rows or columns. For example, in the first formula above, a value for columns is not provided so TAKE returns all 3 columns as a result. Also notice that positive numbers for rows or columns take values from the start of the array .
Take from end
When negative numbers are provided for rows or columns, the TAKE function returns values from the end of the array . In the worksheet below, the first formula in cell F3 returns the last 3 rows of the range B3:D11:
=TAKE(B3:D11,-3)
The formula in F8 returns the last 2 columns of the last 4 rows:
=TAKE(B3:D11,-4,-2)
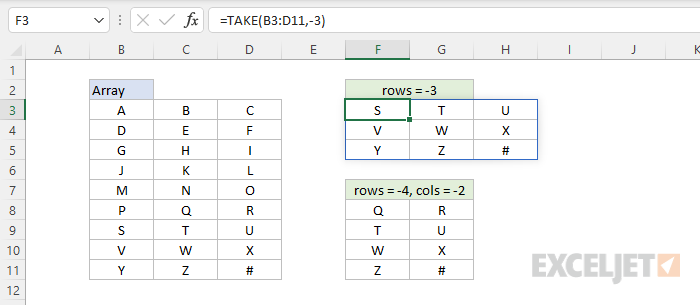
Notice in the first example no value is provided for columns so TAKE returns all columns.
Last column or row
To return the last complete column or row with TAKE, you can use formulas like this:
=TAKE(array,-1) // last row
=TAKE(array,,-1) // last column
Note in the second example the rows argument is simply not provided. Extending these examples, we can get the last 3 rows or columns like this:
=TAKE(array,-3) // last 3 rows
=TAKE(array,,-3) // last 3 columns
TAKE vs. DROP
The DROP and TAKE functions both return a subset of an array, but they work in opposite ways. While the DROP function removes specific rows or columns from an array, the TAKE function extracts specific rows or columns from an array:
=DROP(array,1) // remove first row
=TAKE(array,1) // get first row
Which function to use depends on the situation.
Notes
- Rows and columns are both optional, but at least one must be provided.
- If rows or columns are zero, TAKE returns a #VALUE error.
- If rows > total rows, all rows are returned.
- If columns > total columns, all columns are returned.
Purpose
Return value
Syntax
=TEXTAFTER(text,delimiter,[instance_num],[match_mode],[match_end],[if_not_found])
- text - The text string to extract from.
- delimiter - The character(s) that delimit the text.
- instance_num - [optional] The instance of the delimiter in text. Default is 1.
- match_mode - [optional] Case-sensitivity. 0 = enabled, 1 = disabled. Default is 0.
- match_end - [optional] Treat end of text as delimiter. 0 = disabled, 1 = enabled. Default is 0.
- if_not_found - [optional] Value to return when no match is found. #N/A is default.
Using the TEXTAFTER function
The Excel TEXTAFTER function extracts text that occurs after a given delimiter. When multiple delimiters appear in the text, TEXTAFTER can return text that occurs after the nth instance of the delimiter. TEXTAFTER can also extract text after a specific delimiter when counting from the end of a text string (i.e., get text after the second to the last delimiter).
- The output from TEXTAFTER is a single text string that occurs after a matched delimiter.
- TEXTAFTER takes six arguments, but only the first two are required: text provides the text to process, and delimiter is the substring used to split the text.
- The instance_num argument indicates which instance of the delimiter to use. For example, to extract the text after the second instance of a delimiter, use 2 for instance_num . If not supplied, instance_num defaults to 1.
- By default, TEXTAFTER is case-sensitive ( match_mode = 0) and will match case when looking for a delimiter. S et match_mode to 1 to ignore case when matching delimiters.
- By default, TEXTAFTER will not treat the end of a text string like a delimiter ( match_end = 0). To enable this behavior, set match_end to 1.
- By default, TEXTAFTER will return #N/A when it cannot find the specified delimiter. To return something other than #N/A, provide a value for if_not_found . Note that if match_end is enabled, it will override the value provided for if_not_found.
Note that Excel has three related functions that split text:
- Use TEXTSPLIT to extract all text separated by a given delimiter.
- Use TEXTBEFORE to extract the text before a given delimiter.
- Use TEXTAFTER to extract the text after a given delimiter.
Basic usage
To extract the text that occurs after a specific character or substring, provide the text and the character(s) to use as delimiter in double quotes (""). For example, to extract the first name from “Jones, Bob”, provide a comma in double quotes (",") as delimiter :
=TEXTAFTER("Jones,Bob",",") // returns "Bob"
You can use more than one character for delimiter . For example to extract the second dimension in the text string “12 ft x 20 ft”, use " x “for delimiter:
=TEXTAFTER("12 ft x 20 ft"," x ") // returns "20 ft"
Note we include a space before and after x, since all three characters function as a delimiter.
Text after delimiter with positive instance number
By default instance_num is positive, and TEXTAFTER will count instances of the delimiter starting from the left, as illustrated in the image below. To get all text before “quick”, use 1 for instance number. To get all text before “brown”, use 2 for instance number. To extract all text before the last word in the sentence (“dog”), provide 8 for instance_num:

The formulas below extract text after the first and second occurrence of the hyphen character (”-"):
=TEXTAFTER("ABX-112-Red-Y","-",1) // returns "112-Red-Y"
=TEXTAFTER("ABX-112-Red-Y","-",2 // returns "Red-Y"
TEXTAFTER will return #N/A if the specified instance is not found.
Text after delimiter with negative instance number
One of TEXTAFTER’s special tricks is that it also supports negative instance numbers, which makes it possible to work backward from the last delimiter . When instance_num is negative, TEXTAFTER will count from the right , as illustrated below. To extract the last word in the sentence (“dog”), you would use -1 for instance number:

This is very handy because you don’t need to know how many words are in the sentence to begin with. The formulas below extract text after the last and second-to-last hyphen ("-"):
=TEXTAFTER("ABX-112-Red-Y","-",-1) // returns "Y"
=TEXTAFTER("ABX-112-Red-Y","-",-2) // returns "Red-Y"
If instance_num is out-of-range, TEXTAFTER returns an #N/A error.
Match end of text
Normally, TEXTAFTER does not treat the end of a text string as a delimiter. For example, the formula below asks for the text after delimiter 3, counting from the end (note the negative 3):
=TEXTAFTER("ABX-123-Red-XYZ","-",-3) // returns "123-Red-XYZ"
And this formula returns #N/A because there is no fourth delimiter from the end:
=TEXTAFTER("ABX-123-Red-XYZ","-",-4) // returns #N/A
If we enable match_end by providing 1, the formula behaves as if a delimiter exists before “ABX”, which is the “end” of the string when counting backward.
=TEXTAFTER("ABX-123-Red-XYZ","-",-4,,1) // returns entire string
Take care in situations where a delimiter cannot be found and match_end is enabled. If match_end is enabled and instance_num is 1, TEXTAFTER will return an empty string ("") if delimiter is not found. If match_end is enabled and instance_num is -1, TEXTAFTER will return the entire string if delimiter is not found. When the target delimiter is found, match_end has no effect. The video below demonstrates how the match_end argument can be used:
Multiple delimiters
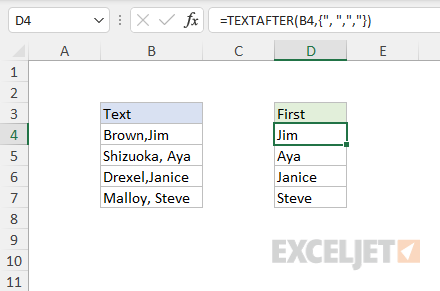
To provide multiple delimiters at the same time to TEXTAFTER, you can use an array constant like {“x”,“y”} where x and y represent different delimiters. One use of this feature is to handle inconsistent delimiters in the source text. For example, in the worksheet below, the delimiter appears as a comma with a space (", “) and a comma without space (”,"). By providing the array constant {", “,”,"} for the delimiter, both variations are handled correctly:
=TEXTAFTER(B4,{", ",","})
Case-sensitivity
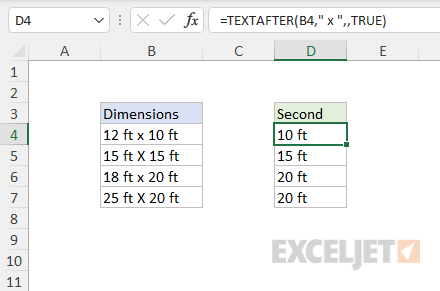
By default, TEXTAFTER is case-sensitive when searching for delimiter . This behavior is controlled by the match_mode argument , a boolean value that enables and disables case-sensitivity. By default, match_mode is FALSE. In the example below, the delimiter appears as both " x " and " X " (upper and lower case “x”). The formula in D4 sets match_mode to TRUE, which disables case-sensitivity and allows TEXTAFTER to match both versions of the delimiter:
=TEXTAFTER(B4," x ",,TRUE) // disable case-sensitivity
Note: you can use 1 and 0 in place of TRUE and FALSE for the match_mode argument.
Notes
- TEXTAFTER is case-sensitive by default.
- TEXTAFTER will return a #N/A! error if delimiter is not found.
- TEXTAFTER will return a #VALUE! error if text is empty
- TEXTAFTER will return #N/A if instance_num is out-of-range.
